Analizando los sueldos de la industria del software en Argentina (Parte 1)
Un tiempo atrás, hicimos una encuesta sobre el estado laboral de los trabajadores de software en Argentina y divulgamos los resultados de la misma, disponibles acá.
Hoy vamos a analizarlos paso a paso, usando el lenguaje R. Todo el código está disponible online con licencia MIT.
Ante cualquier duda, comentario o mejora, abran un ticket en el repo. También respondo por twitter en @fernandezpablo
Data Munging
Los datos se encuentran en formato .csv, que es muy fácil de consumir desde R:
> sueldos <- read.csv('argentina.csv')> nrow(sueldos)
[1] 4001
Perfecto! tenemos 4001 sueldos de argentina. Lamentablemente hay algunos inconvenientes:
- Hay sueldos netos y brutos
- Los nombres de las columnas no son los mejores (“Tengo” para edad, “Qu…tan.conforme.est..s.con.tu.sueldo.”, etc).
- Algunos salarios son obviamente ficticios o están mal ingresados (hay algunos de $1, otros de más de un millón)
Vamos a hacer lo que se denomina data munging que es básicamente transformar los datos para solucionar los problemas descriptos anteriormente. La función que hace esto se puede ver acá.
Los datos “limpios” están en el archivo clean.csv en el repo, por si alguien quiere utilizarlos para crear sus propias visualizaciones.
Histograma
Con los datos en el formato que queremos, podemos empezar con algunas visualizaciones simples. Un histograma que nos muestre la distribución de los salarios, por ejemplo:

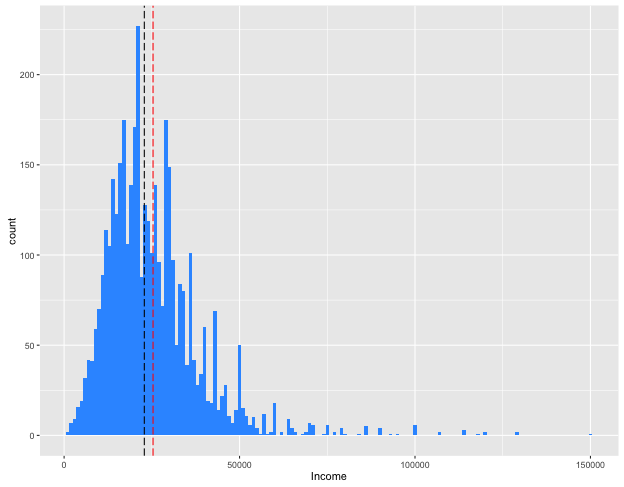
La distribución es right skewed, lo que significa que no simétrica como una distribución normal sino que se “estira” hacia la derecha (ver Skewness). Esto nos indica que hay algunos sueldos muy altos comparados con la media.
Pero ¿cuál es la media? podemos agregar una línea vertical que nos la resalte:

La media está en $25.597,71 (salario bruto, recordemos).
En las distribuciones no normales como ésta, la media no coincide con el centro de la distribución. En estos casos se puede agregar la mediana, que está en $22.857,14:

Otro valor interesante es la moda, el valor que más se repite. En este caso es $21.428,5714. Si bien es un número raro, recuerden que llegamos a él después de nuestra “normalización” de salario neto/bruto. En este caso probablemente se refiere a $15.000 de salario neto (en mano).
Manejo de Outliers
También podemos eliminar los outliers de la muestra, para concentrarnos en el la parte más densa de la distribución. Un método popular para esto es el de Tukey. Antes de “limpiar” los outliers, veamos qué datos nos quitaría de nuestra muestra:

De correr el filtro de Tukey para los outliers, todo salario arriba de $46.571,43 sería descartado (el método también elimina outliers “bajos”, pero en este caso la línea de corte da negativo y por lo tanto no descarta datos).
Los sueldos altos representan en este caso información importante (a mi entender) y por lo tanto no serán descartados para futuros análisis, pero el código disponible permite hacer este recorte cambiando la línea:
clean <- cleanup(df, handleOutliers = identity)
por esta otra:
clean <- cleanup(df, handleOutliers = tukey)
To Be Continued…
Ya tenemos una idea de la distribución y los datos limpios para seguir analizando ¿qué podríamos preguntarnos ahora? Algo interesante sería poder ver la distribución de salario discriminada por sexo:

A simple vista lo que se puede ver es que hay un porcentaje menor de mujeres en nuestra muestra (de hecho son 290 mujeres y 3563 varones) pero ¿las distribuciones son similares? ¿cobran más los hombres o las mujeres en la industria de software argentino?
La respuesta a estos y otros interrogantes más, en el próximo post 😊
Saludos!
Agradecimientos a la gente que comentó y sugirió mejoras: Federico Baylé, Mariano Barrios, Nadia Kazlauskas, Mauro García Aurelio, Román Ávila y Andrés de Barbará.